· Spark SQL · 4 min read
Apache Spark Local Setup Guide

Intro
In this article, we’re going to talk through setting up Apache Spark on your local machine, along with the development environment to follow along with this course.
If you didn’t read our previous post on what is Apache Spark and should you be using it, check it out here
What we are setting up
We are focussed on writing Apache Spark code with Python in this guide. That means we’re going to install the Python Library. We’re going to install Anaconda to manage this process and make it super easy. Then we’re going to make use of Jupyter notebooks to write and run our code.
Anaconda
Anaconda is a free and open-source distribution of the Python and R programming languages for scientific computing, data science, and machine learning. It includes a wide range of packages and tools for data analysis and visualization, as well as popular libraries such as NumPy, Pandas, scikit-learn, and TensorFlow.
One of the main benefits of Anaconda is that it simplifies the process of installing and managing packages and libraries. Instead of installing each package individually, you can use Anaconda to install everything you need in one go. Anaconda also comes with a package manager called conda, which allows you to easily install, update, and remove packages, as well as create and manage virtual environments.
Installing Anaconda
-
Download Anaconda: The first step is to download Anaconda from the Anaconda website (https://www.anaconda.com/products/individual). You should select the version that is compatible with your operating system (e.g., Windows, macOS, or Linux).
-
Install Anaconda: Once the download is complete, open the installation file and follow the prompts to install Anaconda. You may be asked to choose which components to install and where to install Anaconda. It is recommended to accept the default options.
-
Launch Anaconda Navigator: After the installation is complete, launch Anaconda Navigator. This will open a window that allows you to manage your Anaconda installation and launch various applications, including Jupyter notebooks.
Once you’ve completed the steps above, you should see a screen like this
Installing PySpark
Now that you have Anaconda, we can install PySpark really simply.
Open up Anaconda Prompt

Enter the following command, press enter
pip install pyspark
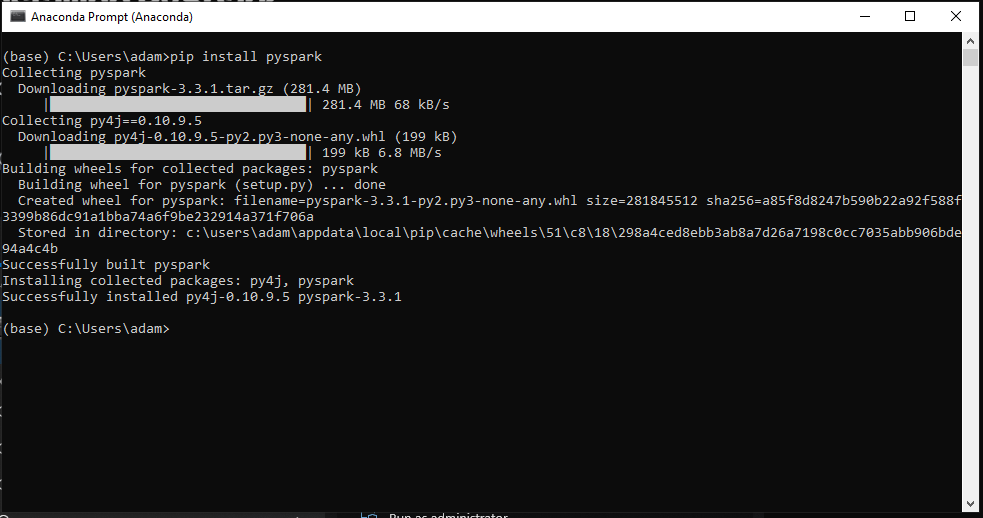
Once that’s done, we’re ready to start writing some code.
Jupyter Notebooks
We’re going to be running our code in Jupyter notebooks. One of the main benefits of Jupyter notebooks is that they allow you to write and run code in a flexible and interactive way. You can mix code blocks with text, equations, and visualizations, and you can run the code blocks one at a time or all at once. This makes it easy to test and debug code, as well as to document and share your work.
To get started, simply hit launch where you see Jupyter in Anaconda Navigator.
This will launch a terminal session, along with a window in your web browser where you can navigate.
If you just want to launch a Jupyter notebook, you can also just search for Jupyter and launch from there
Create a new notebook
I’ve created a folder called Pyspark Tutorial which I will be using to store all of the files for this course.
From there, in the top right you should see a button for new. Simply hit new and choose the Python Notebook.
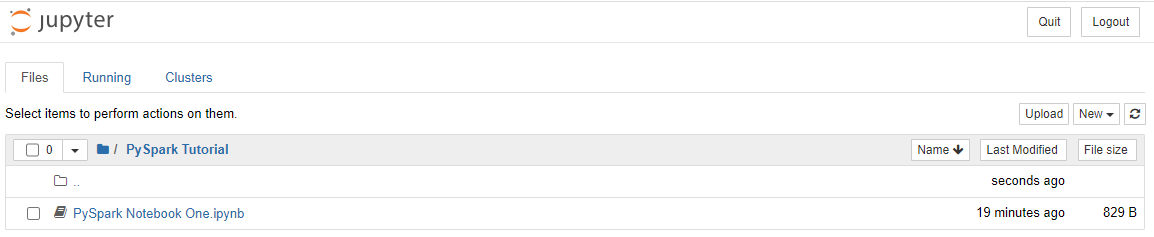
This should launch another web browser window, and you’re now ready to start writing some code!
Jupyter Notebooks
If you’re not familiar with Jupyter notebooks, you can check out our introduction to Jupyter notebooks guide.
In this guide, we will go over some key functionality of Jupyter notebooks that are essential to learn.
Test PySpark is working
We will talk about this more, however let’s just validate that this is working
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
print(type(spark))
The output should be <class 'pyspark.sql.session.SparkSession'>
Let’s look at what this is doing
Creating a Spark Session
-
from pyspark.sql import SparkSession: This imports the SparkSession class from the pyspark.sql module. A SparkSession is used to create a connection to a Spark cluster, and to create DataFrames and Datasets (which are data structures used in Spark). -
spark = SparkSession.builder.getOrCreate(): This creates a SparkSession object. The builder attribute is used to create a SparkSession.Builder, which can be used to configure the SparkSession. The getOrCreate() method creates a SparkSession, or if one already exists, returns the active one.
So, in summary, this code creates a SparkSession object, which is used to create a connection to a Spark cluster and to create DataFrames and Datasets. You will write this code at the beginning of each notebook if you’re developing in a local environment. If you’re working in an integrated environment such as DataBricks, this should already be setup for you and configured on the cluster so you won’t need this code.
Conclusion
Now that you have everything setup and working, we’re ready to start using Apache Spark with Python.